11 min to read
5 AWS Common Mistakes
Doing cloud right

Over the last 7 years, I have been called an AWS DevOps Engineer, AWS Consultant, AWS Sales Representative, and any word after AWS, like AWS Chef, AWS Police, AWS Babysitter, etc.. With that in mind, I have seen a lot of things, and some I wish I had never seen as they were literally stories pulled from a Horror movie. I am talking about how people use AWS and the cloud, from single applications to multi-tier production workloads running on Fortune 500 companies.
I want to share with you the 5 most common mistakes that you should avoid to take advantage of the cloud, and in order of priority that you should focus to implement or validate that you have it in place:
- Not using Infrastructure as code
- Not having observability
- Not using elasticity (ASG)
- Not using Trusted Advisor
- Underutilizing virtual machines
If you are interested in how to avoid these, and get more insights about them, read on.
1. Not using Infrastructure as code

Infrastructure can now be created and managed by using code, one can create 100 servers with pre baked software using a for loop for manage and tag the servers, and all of this created by a CI/CD server triggered by a single commit on a given repository. With this in mind, all the infrastructure for the new application can be created and managed using IaC tools, such as Terraform or Pulumi, which are cloud agnostic, or cloud vendor’s proprietary solutions as AWS Cloudformation or Azure Resources Manager. Cloud providers are now enabling SDKs for a more developer experience/oriented development with more compatibility and capabilities than a given “Provider” on Terraform or even their main IaC solutions.
Choosing the right IaC tool/product will fully depend on the application logic and the level of automation that is needed (which should be the entire stack), but at the end having a complete pipeline for the Infrastructure should be one of the main goals of having our applications running in the cloud as it allows to have a complete control of our systems. Soon after this, we will end up using GitOps methodologies which will increase our agility to deploy not just our applications but our entire infrastructure.
As soon as you have develop your entire infrastructure on any Iac, you are ready to deploy it “n” times with the exact same precision, without any need of human intervention on any of the configurations that your application needs, in terms of inventory management or infrastructure requirements. Is here on where you will be creating all the environments on where the application will live, which normally tends to be development, staging/UAT and production. Sometimes you will also need other environments for testing, experimenting or even innovating and this will be just as easy as running the scripts for creating the very same infrastructure, over and over again.
IaC can help your organization manage IT infrastructure needs while also improving consistency and reducing errors and manual configuration.
Benefits:
- Cost reduction
- Increase in speed of deployments
- Reduce errors
- Improve infrastructure consistency
- Eliminate configuration drift
2. Not having observability (CloudWatch)
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces.
Observability relies on telemetry derived from instrumentation that comes from the endpoints and services in your multi-cloud computing environments. In these modern environments, every hardware, software, and cloud infrastructure component and every container, open-source tool, and microservice generates records of every activity. The goal of observability is to understand what’s happening across all these environments and among the technologies, so you can detect and resolve issues to keep your systems efficient and reliable and your customers happy.
Organizations usually implement observability using a combination of instrumentation methods including open-source instrumentation tools, such as OpenTelemetry.
Many organizations also adopt an observability solution to help them detect and analyze the significance of events to their operations, software development life cycles, application security, and end-user experiences.
Observability has become more critical in recent years, as cloud-native environments have gotten more complex and the potential root causes for a failure or anomaly have become more difficult to pinpoint. As teams begin collecting and working with observability data, they are also realizing its benefits to the business, not just IT.
Because cloud services rely on a uniquely distributed and dynamic architecture, observability may also sometimes refer to the specific software tools and practices businesses use to interpret cloud performance data. Although some people may think of observability as a buzzword for sophisticated application performance monitoring (APM), there are a few key distinctions to keep in mind when comparing observability and monitoring.
Every AWS service reports interesting metrics to a service called CloudWatch. Virtual machines report CPU usage, network usage, and disk activity. Databases report also memory usage and IOPS usage. Mostly all services in AWS have this, so it´s our job to analyze the data, create dashboards, and most importantly, create alerts on stuff that makes sense. Look at the following graph showing CPU usage over a day.
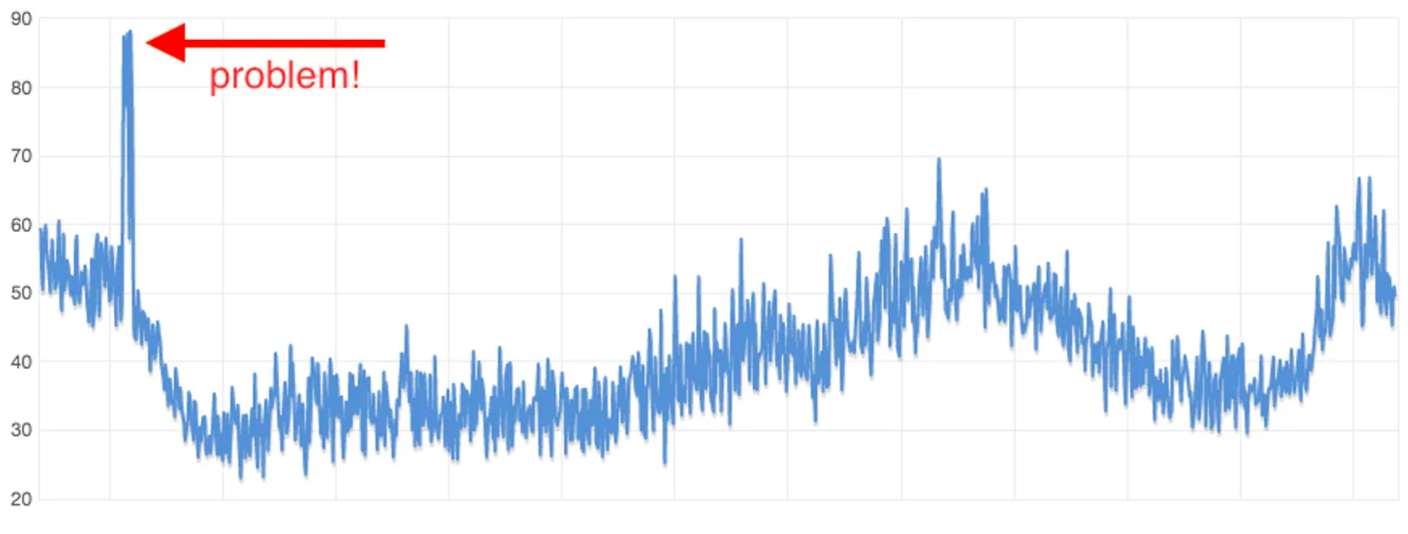
3. Not using elasticity (ASG)
Cloud Elasticity is the property of a cloud to grow or shrink capacity for CPU, memory, and storage resources to adapt to the changing demands of an organization. Cloud Elasticity can be automatic, without the need to perform capacity planning in advance of the occasion, or it can be a manual process where the organization is notified they are running low on resources and can then decide to add or reduce capacity when needed. Monitoring tools offered by the cloud provider dynamically adjust the resources allocated to an organization without impacting existing cloud-based operations.
ASG´s are your best friends.
The biggest problem with Auto Scaling Groups is that people assume that they are about auto-scaling which of course are not! Every EC2 instance should be launched inside an Auto Scaling Group. Even if it’s a single EC2 instance. The Auto Scaling Group takes care of monitoring the EC2 instance, it acts as a logical group of virtual machines, and it’s a free service with no additional cost for usage (Yes, it is!).
In the typical web application, the web servers will run on virtual machines in an Auto Scaling Group. You can of course use Auto Scaling Groups to scale the number of virtual machines based on the current workload but as a precondition, you need Auto Scaling Groups. Auto-scaling is achieved by setting alarms on metrics like CPU usage (of the logical group) or several requests the load balancer received. If the alarm threshold is reached you can define an action like increasing the number of machines in the Auto Scaling Group.
There are now a lot of options for creating your ASGs, with pre-set configurations for autoscaling, scheduled scaling, and so on, let´s deep dive on some of them.
Types of Autoscaling
In a nutshell, autoscaling can be of the following types:
- Reactive: When using a reactive autoscaling method, resources are scaled up and down in response to surges in traffic. This technique is strongly associated with the real-time monitoring of available resources. There is often a cooldown period involved, which is a predetermined time during which resources are maintained at maximum capacity — even when traffic decreases — to cope with any further incremental traffic surges.
- Predictive: A predictive autoscaling method uses machine learning and artificial intelligence tools to evaluate traffic loads and anticipate when you’ll need more or fewer resources. Predictive scaling analyzes each resource’s past workload and predicts the anticipated load for the following two days using machine learning. This is analogous to how weather predictions work. Predictive scaling performs scheduled scaling actions based on the prediction to ensure that resource capacity is available before your application requires it. In other words, Predictive autoscaling applies predictive analytics, including past usage data and current usage patterns, to scale depending on future demand projections automatically.
- Scheduled: Users may choose the time range based on which additional resources will be added. Scheduled autoscaling is a hybrid approach that operates in real-time, predicts known changes in traffic loads, and responds to such changes at predetermined intervals. Scheduled scaling is most effective when there are predictable traffic drops or spikes at specific times of the day, but the changes are usually very abrupt. For example, resources may be pre-provisioned in anticipation of a significant event or a peak time throughout the day, rather than waiting for resources to scale up as demand increases.
- Manual Scaling – In Manual Scaling, the number of instances is manually adjusted. You can manually increase or decrease the number of instances through a CLI or console. Manual Scaling is a good choice when your user doesn’t need automatic Scaling.
- Dynamic Scaling – This is yet another type of Auto Scaling in which the number of EC2 instances is changed automatically depending on the signals received. Dynamic Scaling is a good choice when there is a high volume of unpredictable traffic.
4. Not using Trusted Advisor
AWS Trusted Advisor is also our best friend, ot provides recommendations that help you follow AWS best practices. Trusted Advisor evaluates your account by using checks. These checks identify ways to optimize your AWS infrastructure, improve security and performance, reduce costs, and monitor service quotas. You can then follow the recommendations to optimize your services and resources.
AWS Trusted Advisor Priority helps you focus on the most important recommendations to optimize your cloud deployments, improve resilience, and address security gaps. Available to AWS Enterprise Support customers, Trusted Advisor Priority provides prioritized and context-driven recommendations that come from your AWS account team as well as machine-generated checks from AWS services.
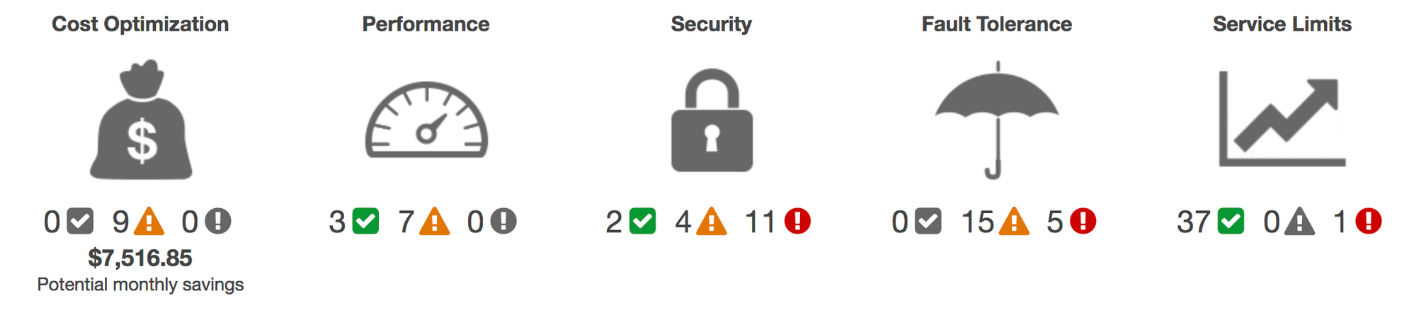
I suggest to care about security first! You can enable a weekly email from Trusted Advisor which tells you what has changed (resolved or new issues) since last week. Activate this in the preferences section. If you pay for AWS support Trusted Advisor becomes even more powerful by adding more checks.
5. Underutilizing virtual machines
Lastly, but certainly not less important, is Underutilizing virtual machines, in this case EC2 instances, this refers to the scenario where EC2 (Elastic Compute Cloud) instances are not being used to their full potential. This can, and will, lead to unnecessary costs and inefficient resource utilization that will add up into your Monthly Bill.
AWS offers several tools and services to help identify cost-saving opportunities:
- AWS Trusted Advisor: This provides real-time guidance to help you provision your resources following AWS best practices, including checks for underutilized resources.
- AWS Cost Explorer: This tool allows you to visualize, understand, and manage your AWS costs and usage over time.
Conclusion
I hope some of these 5 make sense to you, I know they have made sense to all my clients over the past several years working in multiple environments, of course, these are the most common ones I face from project to project, and definitely are the ones I take care first, before jumping into more complex situations and misconfigurations.
Build On!

